
【机器学习】我待机器学习如初恋(入门篇)
一、什么是机器学习
利用计算机从历史数据中找出规律,并把这些规律用来对未来不确定场景的决策。
eg:通过公司第一、第二季度的财报,推测第三季度的营收范围。
从数据寻找规律
数据分析师是靠人来驱动的,依赖数据分析师的经验和知识水平,机器学习是靠机器和程序来驱动的。
数据量越大,找出的规律和决策更精准。
寻找规律的过程,其实在数学上就是寻找通项公式的过程,由于现代计算能力的大幅度提升,CPU/GPU的发展,云计算的发展,我们可以直接对大量数据集进行全量计算,不需要走统计学中的抽样、描述统计、假设检验这套方式,这使得机器学习的准确率在如今可以达到工业级的标准,人工智能也因此登上互联网革命的舞台。
从规律中建立模型
用模型刻画(拟合)规律,主要根据运用数学建模的方式,抽象出一个数学模型,来拟合90%的规律,让程序猿可以进行工程处理。
机器学习发展的原动力
- 从历史数据中找出规律,把这些规律用到对未来自动做出决定。
- 用数据代替
专家叫兽,我们希望数据告诉我们规律,而不是听专家叫兽的。 - 经济驱动,数据变现(原料依托于大数据,变现能力依托于机器学习)。
业务系统发展的历史
- 早期:基于专家经验(出方案,程序猿根据方案编写程序,最终项目的质量瓶颈依托于 专家)。
-
前期:基于统计——分纬度统计(SPSS统计,主要靠数据分析师去建立数据仓库和做报表和方案,再给程序猿编写程序,最终项目的质量瓶颈依托于 数据分析师)
-
现阶段:机器学习——在线学习(新产生一条数据,就实时训练调整模型,实时生成推荐决策)
二、为什么要学习机器学习
呵呵,因为想把数据变成钱,因为很多公司都想把数据变成钱!
三、机器学习典型案例
购物篮分析
- Keyword:关联规则
eg:沃尔玛的啤酒+纸尿裤案例 :纸尿裤和啤酒会很大程度同时被消费者一并购买,根据此现象和规律,沃尔玛对此进行销售策略调整,一下子就扩大了两件商品的销量,这充分利用了数据挖掘中关联规则的算法思想。
用户细分精准营销
- Keyword:聚类
eg:短信电话根据消费人群进行套餐划分:全球通,动感地带,神州行。
垃圾邮件
- Keyword:朴素贝叶斯
eg:以机器学习朴素贝叶斯算法,对垃圾邮件进行分类和过滤。
信用卡欺诈
- Keyword:决策树
eg:运用机器学习的决策树算法,对信用卡人群进行画像和还贷能力区分,提早规避风险。
互联网广告
- Keyword:ctr预估
eg:以百度搜索引擎为例,百度会对每个搜索结果评估出一个点击概率,按照点击概率进行Ranks排序,主要用到的算法就是ctr预估,背后是简单的线性逻辑回归数学问题。
推荐系统
- Keyword:协同过滤
eg:电商购物和浏览商品之后会推荐给用户可能会购买的东西,网易云音乐根据用户产生的历史数据进行每日推荐,猜你喜欢歌曲推荐都是应用到协同过滤的算法规则。
自然语言处理 NLP
PS:这是机器学习中的一个大方向,入门门槛会比机器学习还高,这块后续会单独深入研究,分享学习笔记文章,留个传送门。
- Keyword:情感分析
eg:根据用户在软件产品中的一段评论/文本,判断出用户对于此产品是积极的还是消极的。
- Keyword:实体识别
eg:在一篇文章中,把一些人名,地名,等主干tag提取出来。
图像识别 OCR
PS:这也是机器学习中的一个大方向,入门门槛和NLP一个级别,,这块曾经做个一个简单的毕设项目——基于Tesseract的图文识别搜索引擎,主要运用了Google的开源深度学习库,对字体数据进行训练,有兴趣的朋友可以链接过去看看。
- Keyword:深度学习
四、机器学习和数据分析的区别
数据特点不一样
交易数据 VS 行为数据
- 交易数据:订单,存取款账单等和钱相关的数据,一致性要求高。
-
行为数据:用户搜索历史,点击历史,浏览历史,评论等,不要求精准一致性。
少量数据 VS 海量数据
- 少量数据:GB级别以下
-
海量数据:TB,PB级别量
采样分析 VS 全量分析
- 采样分析:对数据进行小规模采样,提取粗略特征。
-
全量分析:全量数据需要利用到Hadoop等一些大数据平台来支撑计算,提取出精准特征。
解决业务问题不同
简而言之:数据分析主要是追溯历史,而机器学习是预测未来!
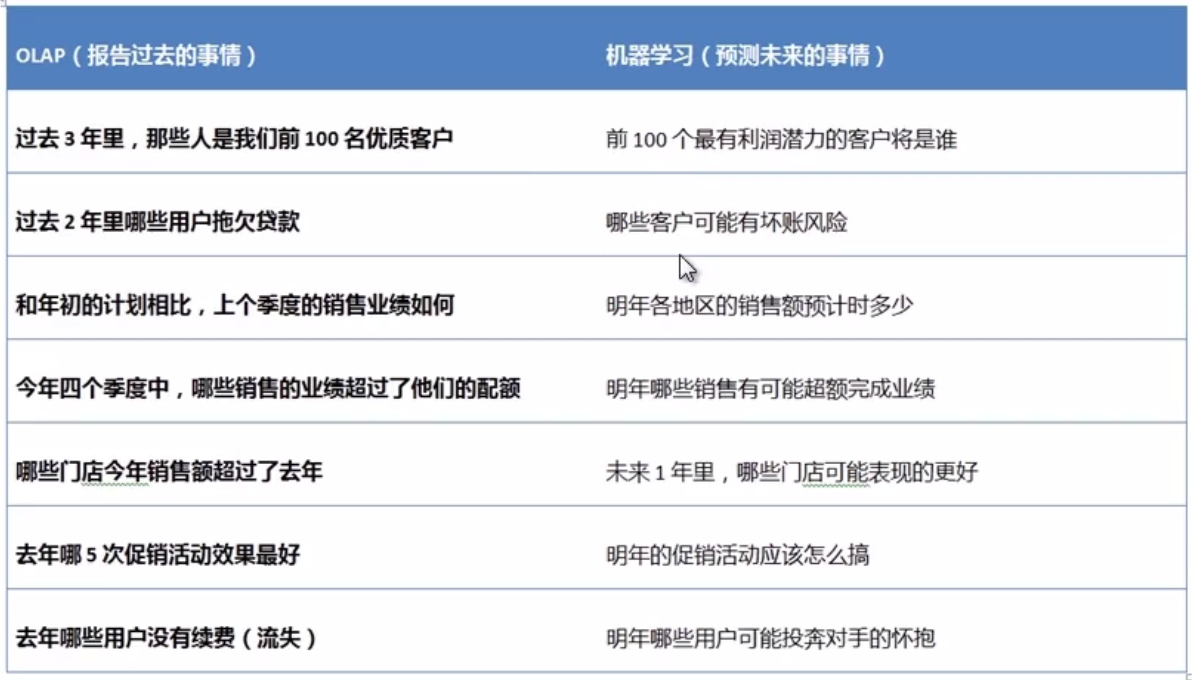
技术手段不同
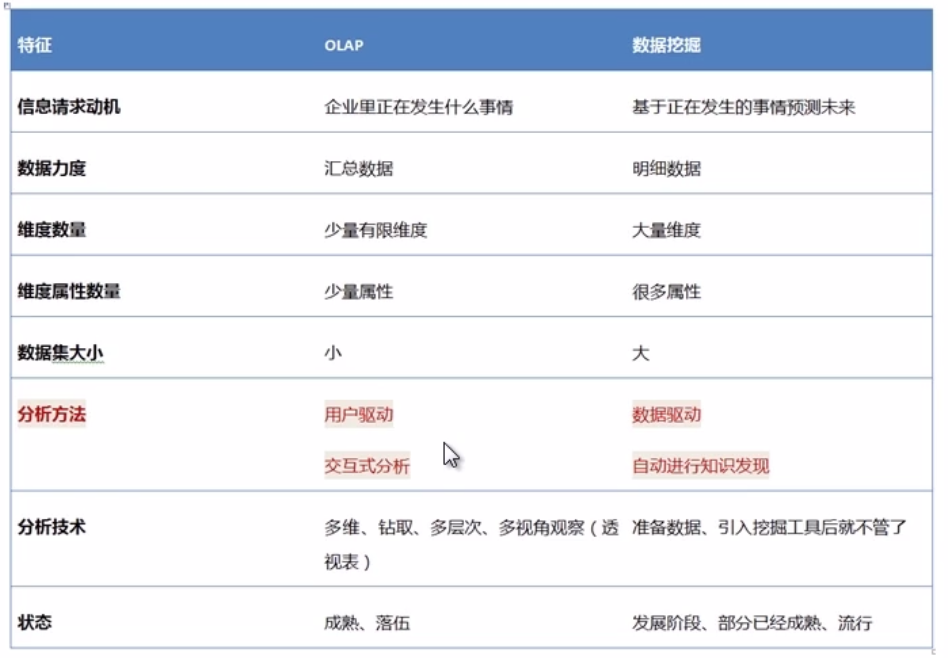
参与者不同,导向不同

五、机器学习算法
需要一定的高等数学基础:概率论和统计学。
按宏观分类
有监督学习
在训练数据中,已经明确给出了Y值,已经明确给出每一个样本属于哪一个类别,已提前打好标签。
无监督学习
在训练数据中,并没有Y值,我们自己都不知道。需要靠聚类算法来拟合Y值。
半监督学习
先有Y值,后根据样本数据的完善,不断训练更准确的Y值。
按算法类型分类
分类
回归
聚类
标注
切词,一句话,提取主语,动词,形容词等,打上标注。
按模型分类
生成模型:无穷样本==》概率密度模型 = 产生模型==》预测
生成方法由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)=P(X,Y)/P(X)作为预测的模型。这样的方法之所以成为生成方法,是因为模型表示了给定输入X产生输出Y的生成关系。用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。典型的生成模型有:朴素贝叶斯法、马尔科夫模型、高斯混合模型。这种方法一般建立在统计学和Bayes理论的基础之上。
判别模型:有限样本==》判别函数 = 预测模型==》预测
判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。判别方法关心的是对给定的输入X,应该预测什么样的输出Y。典型的判别模型包括:k近邻法、感知机、决策树、逻辑斯蒂回归模型、最大熵模型、支持向量机、boosting方法和条件随机场等。判别模型利用正负例和分类标签,关注在判别模型的边缘分布。
常见算法一览
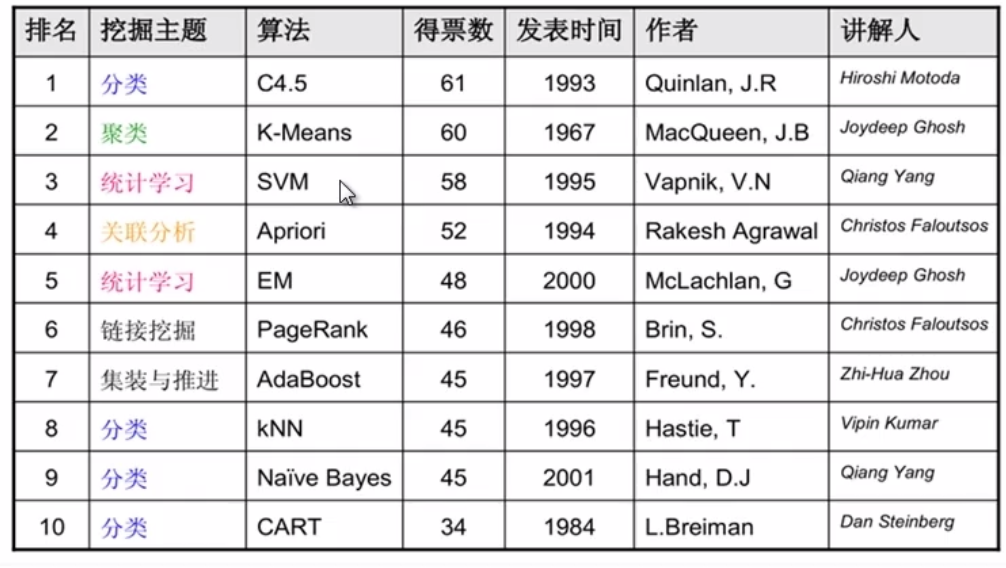
还有一些排名不靠前,但是很实用的:
- FP-Growth
-
逻辑回归
-
RF(随机森林)、GBDT
-
LDA
-
Word2Vector
-
HMM、CRF
-
推荐算法
-
深度学习
六、机器学习解决问题的WorkFlow
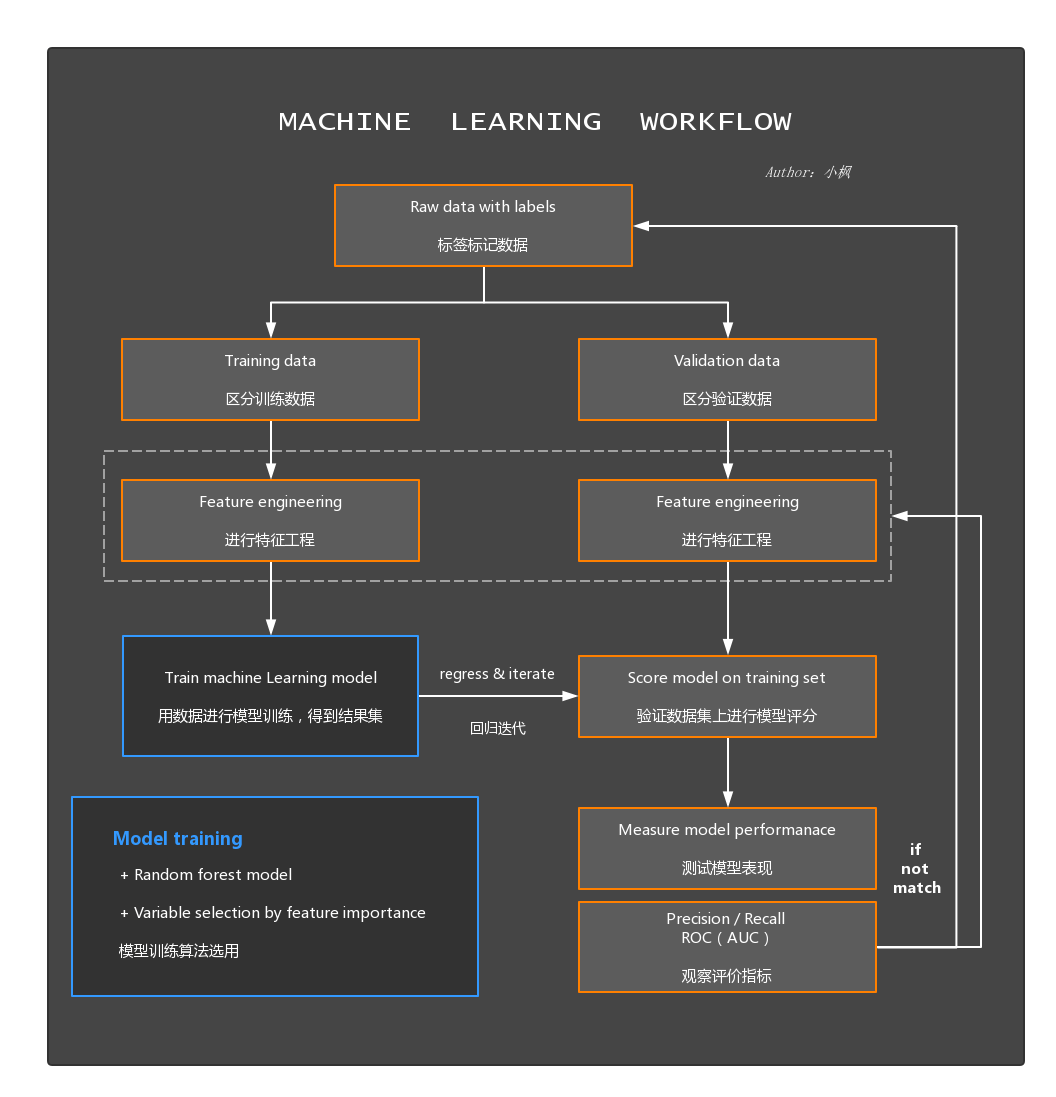
如果无法理解上述图片内容,我归纳workflow如下:
确定目标
- 业务需求
- 数据
- 特征工程
训练模型
- 定义模型
- 定义损失函数(偏差大小)
- 优化算法
模型评估
- 交叉验证
- 效果评估
七、框架
TensorFlow | Google出品 | 是深度学习框架里的明星产品 | 全英文,比较权威

PaddlePaddle | Baidu出品 | 是深度学习框架里的新星产品 | 对中文支持友好
八、Demo
自己运用一些机器学习的知识,编写的一个小Demo
请移步:【机器学习】我待机器学习如初恋(实战篇)- 预测比特币涨跌趋势Demo

Comments | NOTHING